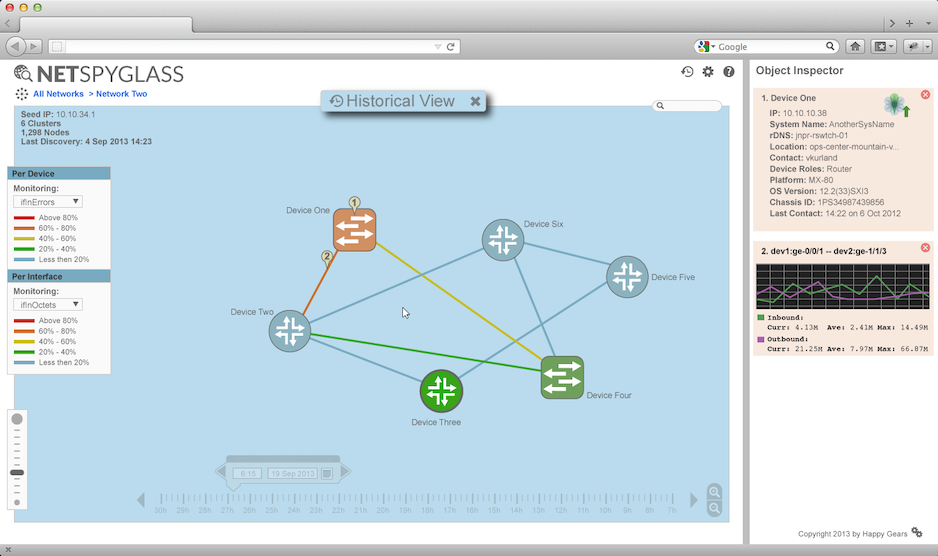
Outcomes
When the first version of Netspyglass launched it took some time and leg work on our part for
it to be adopted. In particular it required sitting in a NOC at Dropbox headquarters in San
Francisco with operators, installing an instance and allowing it to discover their network
and then demonstrating the ease with which issues can be identified and analyzed. Once they saw
what the tool could do they agreed to a formal POC in their NOC that resulted in them becoming
our first real customer. Not long after, deals were signed with The Gap, and several other smaller
enterprises.
An Interesting Conversation
Sometime after being adopted by Dropbox my wife and I were preparing to rent out a condo that
we have in Mountain View, and I was asking the new renters what they did for a living. He
replied that he worked at Dropbox in the operations center. When I asked what he did, he said
he wasn't sure how to explain it without knowing what my background was. I
told him I'd worked at Juniper Networks, and several other networking startups, and hearing this
he simply said he monitored network issues and kept things running smoothly.
Realizing he may have heard of the product, I told him that I'd designed a tool they used at Dropbox
called Netspyglass and he replied excitedly that, "NSG is my go to tool at work! I love
that application!"
Of all the ad hoc feedback I have received in my career, this remains one the things I'm most proud of hearing
about something I designed.
Learnings
This project offered several key learnings. First, that although the tenant that you have to know
your user is very true, it's also important to understand the overlap of different types of users.
In retrospect it seems obvious, but we were so focused on building the right tool for each that we
missed the other truth; users may need very similar tools even if their roles are not identical. If
we'd gone through a more formal and traditional requirement gathering phase we may have been noticed
this sooner.
Another interesting thing that we discovered was that the old Apple saw, "Think Different" could easily
be applied to almost any problem. For us, this meant that if when we were trying to identify our
applications value proposition, we may have been better off to simply ask various sets of users
(like my wife), "What is the problem and if you could have any magical solution what would that do for you?"
My wife insists that there is a third key learning: listen to your wife. While I do think she has
a point, she'd be the first to tell you that I've not fully integrated this one into my approach to life.